Qlib的日频数据测试
引言
LightGBM1是在GBDT算法框架下的一种改进实现,是一种基于决策树算法2的快速、分布式、高性能的GBDT框架。“Light”主要体现在三个方面,即更少的样本、更少的特征、更少的内存,分别通过单边梯度采样(Gradient-based One-Side Sampling)、互斥特征合并(Exclusive Feature Bundling)、直方图算法(Histogram)三项技术实现。“微矿 Qlib”3是微软亚洲研究院2020年12月9日正式发布的AI量化投资开源平台。其中包含LightGBM等算法基于pytorch的实现,还自带Alpha158 和 Alpha360 因子库。(不是算好的因子参数,而是一套生成因子的算法)。
环境搭建
使用Windows10(21H2)结合docker-desktop和wsl2搭建测试环境。
Windows10安装
测试环境的系统版本信息如下:
> systeminfo
OS Name: Microsoft Windows 10 IoT 企业版 LTSC
OS Version: 10.0.19044 N/A Build 19044
……
Processor(s): 1 Processor(s) Installed.
[01]: Intel64 Family 6 Model 140 Stepping 1 GenuineIntel ~2803 Mhz
……
Total Physical Memory: 16,082 MB
……
Hotfix(s): 5 Hotfix(s) Installed.
[01]: KB5008876
[02]: KB5003791
[03]: KB5009543
[04]: KB5007273
[05]: KB5005699
安装wsl2
Windows10的内部版本号必须高于18362或18363,次要内部版本号需要高于.1049。
启用wsl功能
以管理员身份打开 PowerShell(右键“开始”菜单 >“Windows PowerShell(管理员)”),然后输入以下命令,
> dism.exe /online /enable-feature /featurename:Microsoft-Windows-Subsystem-Linux /all /norestart
启用虚拟机功能
安装 WSL 2 之前,必须启用“虚拟机平台”可选功能。 计算机需要虚拟化功能才能使用此功能。
以管理员身份打开 PowerShell 并运行,
> dism.exe /online /enable-feature /featurename:VirtualMachinePlatform /all /norestart
重新启动系统
Linux内核更新
下载 Linux 内核更新包
运行上一步中下载的更新包。 (双击以运行 - 系统将提示你提供提升的权限,选择“是”以批准此安装。)
重新启动系统。
将 WSL 2 设置为默认版本
将 WSL 2 设置为默认版本
> wsl --set-default-version 2
下载ubuntu20.04安装包
进入 Downloading distributions 选择合适的系统安装包。
这里选择ubuntu20.04。
因为笔者的C盘只有120GB,所以下载到D盘wsl目录下。将下载的文件解压后,运行ubuntu2004.exe 完成安装wsl并设置用户名和密码。
安装Docker
下载 Docker Desktop for Windows 升级到最新版本
> docker --version
Docker version 20.10.22, build 3a2c30b
迁移数据(可选项)
因为笔者的C盘只有120GB,所以笔者把docker的镜像也移到D盘docker目录下。基于WSL2的版本的docker desktop在安装的时候创建两个wsl子系统。
> wsl -l -v --all
NAME STATE VERSION
* docker-desktop Running 2
docker-desktop-data Running 2
Ubuntu-20.04 Running 2
可以看到docker-desktop用于存放程序文件,docker-desktop-data用于存放docker镜像,这两个wsl子系统都是默认放在系统盘的。
导出wsl子系统镜像
> wsl --export docker-desktop D:\docker\wsl\docker-desktop.tar
wsl --export docker-desktop-data D:\docker\wsl\docker-desktop-data.tar
删除现有的wsl子系统
> wsl --unregister docker-desktop
wsl --unregister docker-desktop-data
导入wsl子系统
> wsl --import docker-desktop D:\docker\wsl D:\docker\wsl\docker-desktop.tar --version 2
wsl --import docker-desktop-data D:\docker\data D:\docker\wsl\docker-desktop-data.tar --version 2
安装pytorch
注意:到2024年,基于docker的cuda方案已经很成熟了。建议直接使用docker安装,不建议本地安装。
——以下是以前的做法。
为了利用显卡的算力,尽可能安装cuda版本的pytorch。
打开 PowerShell(“开始”菜单 >“PowerShell”)输入 nvidia-smi
> nvidia-smi
Thu Jan 28 20:19:28 2022
+-------------------------------------------------------------------+
| NVIDIA-SMI 472.47 Driver Version: 472.47 CUDA Version: 11.4 |
+------------------+----------------------+-------------------------+
可以看到,显卡 在版本为472.47的驱动程序支持下,最高支持的CUDA Version为11.4。
查看当前PyTorch Stable Build 为 1.10.1。支持CUDA 11.3 。因此,安装CUDA 11.3。
打开 PowerShell(“开始”菜单 >“PowerShell”)输入 wsl.exe -d Ubuntu-20.04
cd ~
wget http://mirrors.aliyun.com/nvidia-cuda/wsl-ubuntu/x86_64/cuda-wsl-ubuntu.pin
sudo mv cuda-wsl-ubuntu.pin /etc/apt/preferences.d/cuda-repository-pin-600
sudo add-apt-repository "deb https://mirrors.aliyun.com/nvidia-cuda/wsl-ubuntu/x86_64/ /"
sudo apt-key adv --recv-keys --keyserver keyserver.ubuntu.com 7fa2af80
sudo apt-key adv --fetch-keys http://mirrors.aliyun.com/nvidia-cuda/wsl-ubuntu/x86_64/7fa2af80.pub
sudo apt update
sudo apt upgrade
sudo apt install cuda-11-3
pip3 install torch==1.10.1+cu113 torchvision==0.11.2+cu113 torchaudio==0.10.1+cu113 -f https://download.pytorch.org/whl/cu113/torch_stable.html
vim ~/.bashrc
export DISPLAY=$(cat /etc/resolv.conf | grep nameserver | awk '{print $2; exit;}'):0.0
export CUDA_HOME=/usr/local/cuda
export PATH=$PATH:$CUDA_HOME/bin
export LD_LIBRARY_PATH=/usr/local/cuda-11.3/lib64${LD_LIBRARY_PATH:+:${LD_LIBRARY_PATH}}
export PATH=$PATH:/home/rossea/.local/bin
source ~/.bashrc
安装vscode(非必须)
为了便于调试,可以在windows下安装 Visual Studio Code For Windows (System Installer)( 64 bit) 并安装wsl下的相应扩展。 这里使用的扩展如下,需要手工安装,比如:
# $code --install-extension MS-CEINTL.vscode-language-pack-zh-hans@1.63.3
$ code --list-extensions
MS-CEINTL.vscode-language-pack-zh-hans
ms-azuretools.vscode-docker
ms-python.python
ms-python.vscode-pylance
ms-toolsai.jupyter
ms-toolsai.jupyter-renderers
安装qlib
详见 qlib的文档
cd ~/
mkdir src
cd src
pip install numpy
pip install --upgrade cython
git clone https://github.com/microsoft/qlib.git && cd qlib
如github失效,使用
git clone https://github.com.cnpmjs.org/microsoft/qlib.git && cd qlib
python3 setup.py install
获取示例数据
python3 scripts/get_data.py qlib_data --target_dir ~/.qlib/qlib_data/cn_data --region cn
# 测试安装
code examples/workflow_by_code.ipynb
数据获取
Qlib 支持用户提供的 csv 格式数据,需要调用 dump_all 指令将 csv 格式数据转换为 bin 和 txt 格式。 股票 csv 数据需要至少包含stock_code, date, open, high, low, close, volume, money, factor字段。 价格数据建议采用复权价格,因”module_path”: “qlib.contrib.data.handler”采用 close 计算股票未来收益率,且 qlid.contrib.evaluate.backtest 使用 close、open 进行交易回测。且数据需包含 factor 或 change 字段,否则运行 Qlib 代码示例 examples/workflow_by_code.py 时,策略收益计算将出现异常。
有同学考虑能否让Qlib直接从mongodb里读取数据。研究发现Qlib 底层为此设计了专用的数据库,即交易日历索引和二进制文件的形式,将文件组织成一种树状结构,数据存放在不同目录下的不同文件中,依据频率、属性和测度来分类。 ,交易日历轴存放于calendar.txt 文件中,用于按时间查询的操作。右半部分为所有属性数据用二进制文件存储,共有(N+1)*4位,前4位存放时间戳信息,用于匹配交易日历,程序能直接按位索引取数。相当于直接通过地址指针存取数据,以解决算法遍历数据时的多次索引问题,降低时间复杂度。
如果改为从mongodb里读取数据,则无法使用此机制。另外qlib的二级缓存设计也是针对此种数据存储结构。
所以,这里采用从外部导入数据的方法进行测试。
安装QUANTAXIS
QUANTAXIS4项目进行了大量基础数据的整理工作。为了尽快获得数据,这里直接使用docker拉取QUANTAXIS的镜像进行安装。
cd /mnt/d/docker
mkdir qa
cd qa
wget https://raw.githubusercontent.com/QUANTAXIS/QUANTAXIS/master/docker/qaservice_docker.sh
sudo docker volume create qamg
sudo docker volume create qacode
sudo docker-compose up -d
sudo docker-compose restart
#在终端界面输入"/bin/bash",进入bash状态;
#bash状态下,pip方式安装群文件里的quantaxis-1.10.19r3-py3-none-any和pytdx-1.72r2-py3-none-any两个包,成功后输入"quantaxis",进入数据库操作状态;
#依次输入完成数据库初始化"save stock_list","save single_index_day 000300"
#获取股市日线数据"save all" (要运行大约4个小时,视网络情况而定)
从QUANTAXIS导出数据
在qacommunity-rust所在容器中导出数据,存储到volumes: - qacode:/root/code目录中。qa中部分指数数据导出时会出错。所以只导入000开头的184个指数数据。
# exp2qlib.ipynb
import QUANTAXIS as QA
import pandas as pd
def write_stock_csv(str_code,str_sse):
QA.QA_fetch_stock_day_adv(str_code,'1990-01-01','2022-01-25').to_qfq().data.to_csv('tmp_stock/'+str_sse+str_code+'.csv')
# rename columns for qlib
qlib_df = pd.read_csv('tmp_stock/'+str_sse+str_code+'.csv')
qlib_df = qlib_df.rename(columns={'code':'stock_code','adj':'factor','amount':'money'}).to_csv('tmp_stock/'+str_sse+str_code+'.csv',index=0)
def write_index_csv(str_code,str_sse):
QA.QA_fetch_index_day_adv(str_code,'1990-01-01','2022-01-25').data.to_csv('tmp_index/'+str_sse+str_code+'.csv')
# rename columns for qlib
qlib_df = pd.read_csv('tmp_index/'+str_sse+str_code+'.csv') # tmp.csv for test
qlib_df = qlib_df.rename(columns={'code':'stock_code','amount':'money'}).to_csv('tmp_index/'+str_sse+str_code+'.csv',index=0)
table_stock_list = QA.QA_fetch_stock_list()
for index,row in table_stock_list.iterrows():
try:
write_stock_csv(row['code'],row['sse'])
except:
print(row['code'])
table_index_list = QA.QA_fetch_index_list()
for index,row in table_index_list.iterrows():
try:
write_index_csv(row['code'],row['sse'])
except:
print(row['code'])
将数据导入qlib
发现在Ubuntu-20.04中,无法访问docker-desktop-data的共享卷,原因不明。
$ ls /mnt/wsl/docker-desktop-data/version-pack-data/community/docker/volumes/qacode/_data/tmp_stock
ls: cannot access '/mnt/wsl/docker-desktop-data/version-pack-data/community/docker/volumes/qacode/_data/tmp_stock': No such file or directory
# 解决方法,通过Windows资源管理器打开\\wsl$\docker-desktop-data\version-pack-data\community\docker\volumes\qacode_data
# 将tmp_index和tmp_stock 文件夹复制到wsl可访问的位置。如D:\data\
mkdir ~/.qlib/qlib_data/qa_data
- 全新导入股票数据
python3 scripts/dump_bin.py dump_all --csv_path /mnt/d/data/tmp_stock --qlib_dir ~/.qlib/qlib_data/qa_data --symbol_field_name stock_code --date_field_name date --include_fields open,high,low,close,volume,money,factor
- 追加导入指数数据
python3 scripts/dump_bin.py dump_fix --csv_path /mnt/d/data/tmp_index --qlib_dir ~/.qlib/qlib_data/qa_data --symbol_field_name stock_code --date_field_name date --include_fields open,high,low,close,volume,money
- 建立csi300指标
python3 scripts/data_collector/cn_index/collector.py --index_name CSI300 --qlib_dir ~/.qlib/qlib_data/qa_data --method parse_instruments
- 获取未来交易日历
python3 scripts/data_collector/contrib/future_trading_date_collector/future_trading_date_collector.py --qlib_dir ~/.qlib/qlib_data/qa_data --freq day
测试导入数据
修改示例代码
code examples/workflow_by_code.ipynb
# use default data
# NOTE: need to download data from remote: python scripts/get_data.py qlib_data_cn --target_dir ~/.qlib/qlib_data/cn_data
provider_uri = "~/.qlib/qlib_data/qa_data" # target_dir 修改数据目录为新导入的 "~/.qlib/qlib_data/qa_data"
# if not exists_qlib_data(provider_uri): # 屏蔽yahoo示例数据获取代码段
# print(f"Qlib data is not found in {provider_uri}")
# sys.path.append(str(scripts_dir))
# from get_data import GetData
# GetData().qlib_data(target_dir=provider_uri, region=REG_CN)
qlib.init(provider_uri=provider_uri, region=REG_CN)
将示例代码数据截至时间 “2020-08-01”改为新导入的”2022-01-01”。全部运行。
运行结果
# train model 用时1m47.7s
Training until validation scores don't improve for 50 rounds
[20] train's l2: 0.989331 valid's l2: 0.994386
[40] train's l2: 0.985445 valid's l2: 0.993802
[60] train's l2: 0.982684 valid's l2: 0.993508
[80] train's l2: 0.980237 valid's l2: 0.993342
[100] train's l2: 0.978197 valid's l2: 0.993164
[120] train's l2: 0.976154 valid's l2: 0.99316
[140] train's l2: 0.974282 valid's l2: 0.993243
[160] train's l2: 0.972436 valid's l2: 0.993311
[214:MainThread](2022-01-28 22:35:10,749) INFO - qlib.timer - [log.py:113] - Time cost: 0.000s | waiting `async_log` Done
Early stopping, best iteration is:
[119] train's l2: 0.976263 valid's l2: 0.993154
# prediction, backtest & analysis
'The following are analysis results of benchmark return(1day).'
risk
mean 0.000402
std 0.012030
annualized_return 0.095590
information_ratio 0.515048
max_drawdown -0.370479
'The following are analysis results of the excess return without cost(1day).'
risk
mean 0.000776
std 0.006267
annualized_return 0.184801
information_ratio 1.911490
max_drawdown -0.093099
'The following are analysis results of the excess return with cost(1day).'
risk
mean 0.000576
std 0.006266
annualized_return 0.137135
information_ratio 1.418684
max_drawdown -0.096577
'The following are analysis results of indicators(1day).'
value
ffr 1.0
pa 0.0
pos 0.0
## analysis position
为了保存Jupyter运行结果,还需要安装nbconvert
pip install nbconvert
sudo apt-get install texlive-xetex texlive-fonts-recommended texlive-plain-generic
sudo apt-get install pandoc
pip install pyppeteer
模型优化
经过前期工作,程序基本框架已经建立。效率仍有优化空间。
调参方向
考虑通过The tuner pipeline或Optuna等进行调参优化.
优化结果
测试结果
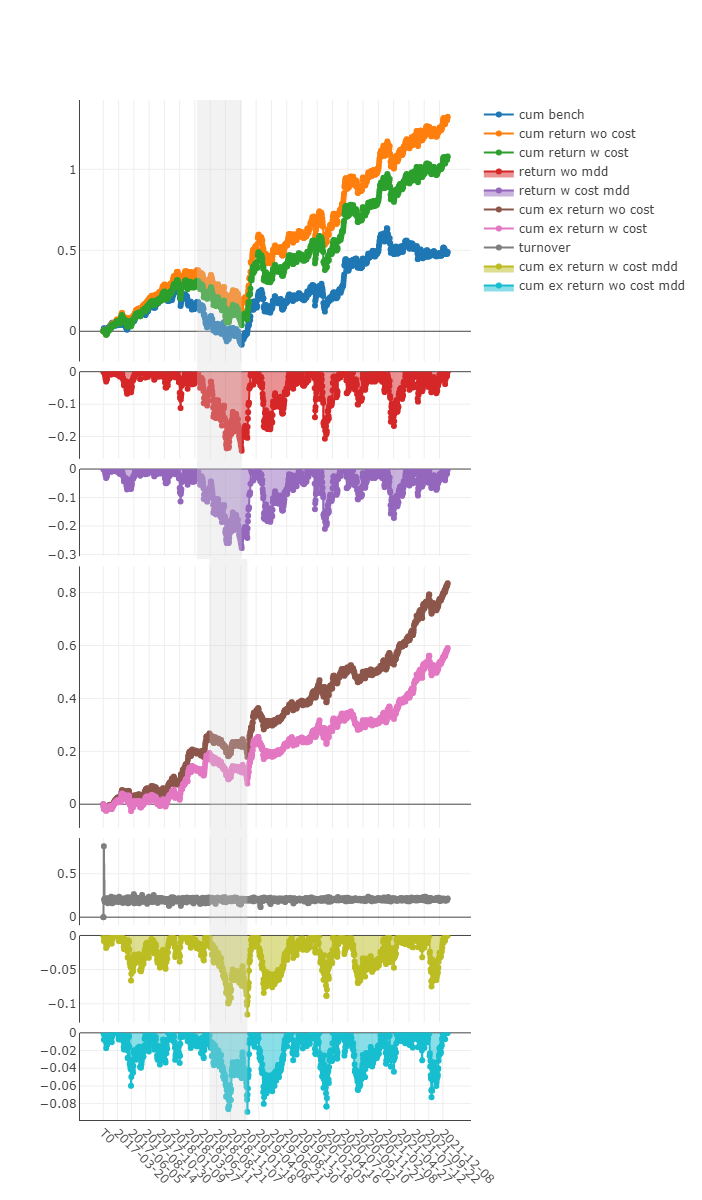
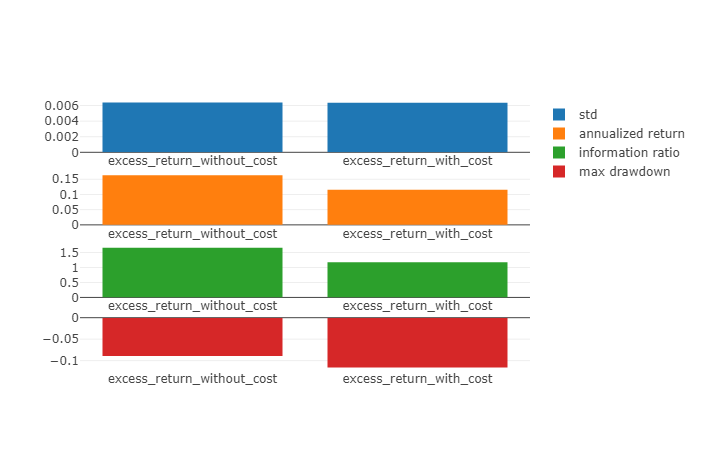
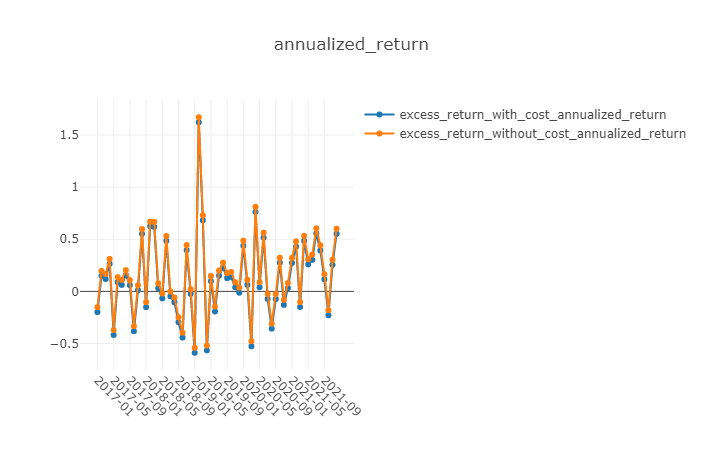
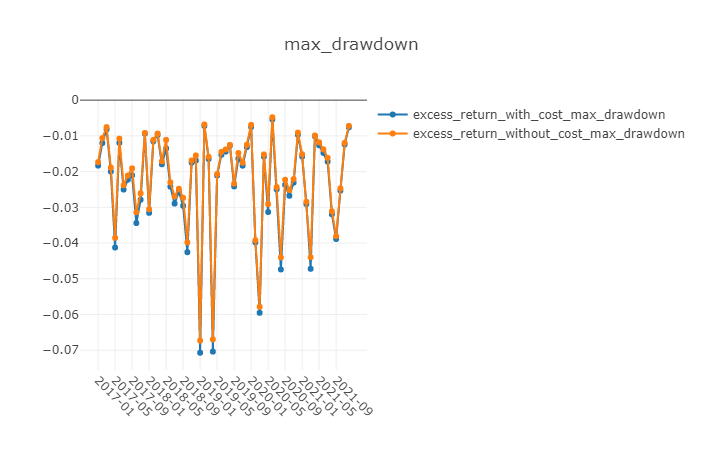
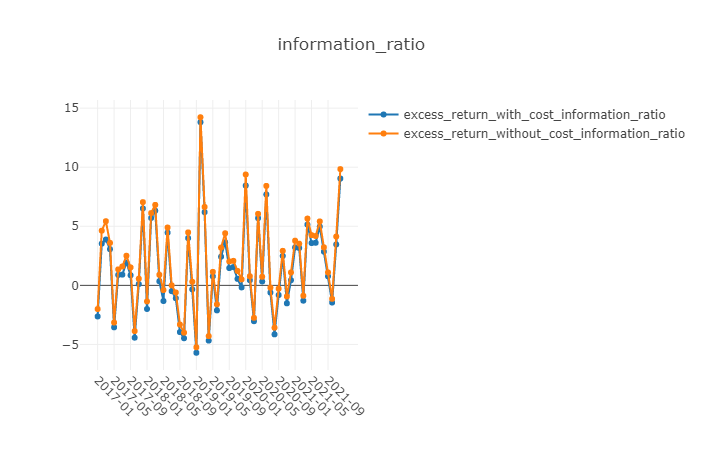
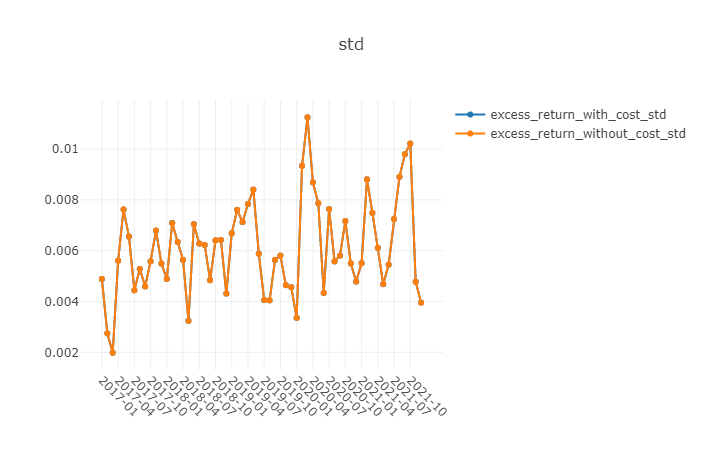
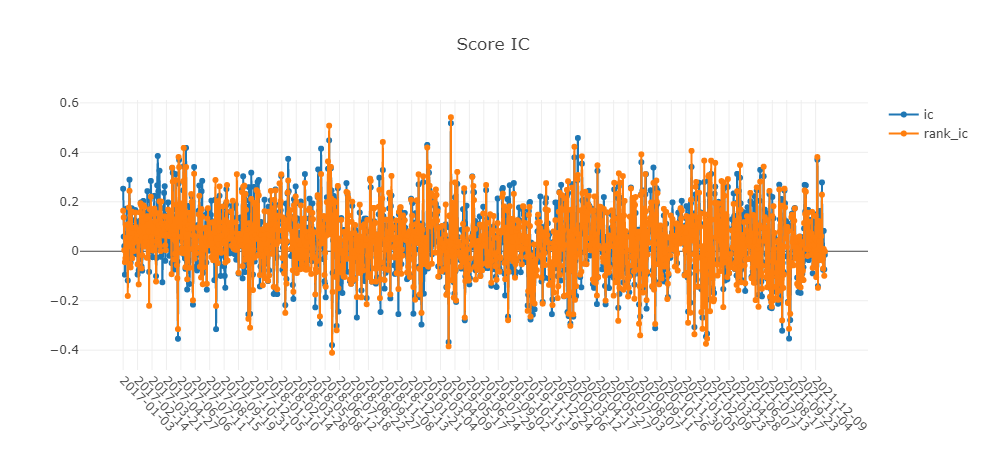
优势
(1)Qlib全部使用python语言开发,确实降低 AI 算法使用门槛;
(2)对因子数据储存的数据结构进行改进,提高了遍历样本数据的性能。从GBDT到XGBoost再到LightGBM这类树形分类算法耗时最多的部分是对样本数据的遍历。LightGBM使用的Histogram算法基本思想是先把连续的浮点特征值离散化成k个整数,构造一个宽度为k的直方图。在遍历数据的时候,根据离散化后的值作为索引在直方图中累积统计量,当遍历一次数据后,直方图累积了需要的统计量,然后根据直方图的离散值,遍历寻找最优的分割点。直方图算法不仅不需要额外存储预排序的结果,而且可以只保存特征离散化后的值,而这个值一般用8位整型存储就足够了,内存消耗可以降低为原来的1/8。然后在计算上的代价也大幅降低,预排序算法每遍历一个特征值就需要计算一次分裂的增益,而直方图算法只需要计算k次;
(3)Qlib的 AI 选股模型包含因子生成和预处理、模型训练、策略回测等组件,通过qrun命令调用qlib.workflow,定义的主要参数格式规整,便于修改。各模块代码风格统一,便于修改;
(4) 自带原生调参组件The tuner pipeline。(未测试)
劣势
(1)缺少日频数据、分钟级实时数据的获取接口;
(2)对于Portfolio Strategy(建立投资组合)的方法,在文档中只找到 TopkDropoutStrategy一种实现。如需自定义组合构建方式,需要通过继承 qlib.contrib.strategy.BaseStrategy 类的方式创建新的策略类;
(3)和QUANTAXIS项目面向全流程的功能相比,qlib侧重于策略开发、回测的择股环节。缺少择时交易部分的功能。Qlib如果想用于实盘,仍然需要大量工作。
参考
- [1] KE G, MENG Q, FINLEY T, et al. Lightgbm: A highly efficient gradient boosting decision tree[J]. Advances in neural information processing systems, 2017, 30: 3146-3154.
- [2] MENG Q, KE G, WANG T, et al. A communication-efficient parallel algorithm for decision tree[A]. 2016.
- [3] YANG X, LIU W, ZHOU D, et al. Qlib: An ai-oriented quantitative investment platform[A]. 2020.
- [4] YUTIANSUT. quantaxis[EB/OL]. 2016. https://github.com/QUANTAXIS/QUANTAXIS.
免责声明:
本文档的表达为个人观点;彼以往、现在或未来并无就本文档所提供的具体建议或所表迖的观点直接或间接收取任何报酬。通过本文档引证及推论的结果并不构成本人对投资的任何具体意见。